Learning Sensorimotor Agency
in Cellular Automata
Finding robust self-organizing "agents" with gradient descent and curriculum learning: individuality, self-maintenance and sensori-motricity within a cellular automaton environment
What you will find in this blog 📝
Abstract
Novel classes of Cellular Automata (CA) have been recently introduced in the Artificial Life (ALife) community, able to generate a high diversity of complex self-organized patterns from local update rules. These patterns can display certain properties of biological systems such as a spatially localized organization, directional or rotational movements, etc. In fact, CA have a long relationship with biology and especially the origins of life/cognition as it is a self-organizing system that can serve as a computational testbed and toy model for such theories but also as a source of inspiration on what are the basic building block of "life". However, while the notions of embodiment within an environment, individuality individuality: ability of an informational/physical structure to preserve its coherence and integrity and self-maintenance self-maintenance: capacity of a structure to modify its interactions with the rest of the environment for maintaining its integrity are central in theoretical biology and in particular in the definition of agency (e.g. Maturana & Varela , Varela ), it remains unclear how such mechanisms and properties can emerge from a set of local update rules in a CA. In this blogpost, we propose an approach enabling to learn self-organizing agents capable of reacting to the perturbations induced by the environment, i.e. robust agents with sensorimotor capabilities. We provide a method based on curriculum learning, on diversity search and on gradient descent over a differentiable CA able to discover the rules leading to the emergence of such creatures. The creatures obtained, using only local update rules, are able to regenerate and preserve their integrity and structure while dealing with the obstacles or other creatures in their way. They also show great generalization, with robustness to changes of scale, random updates or perturbations from the environment not seen during training. We believe that the field of artificial intelligence could benefit from these capabilities of self-organizing systems to make robust intelligent systems that can quickly adapt to new environments and to perturbations.
Interactive Demo
Zoomed in
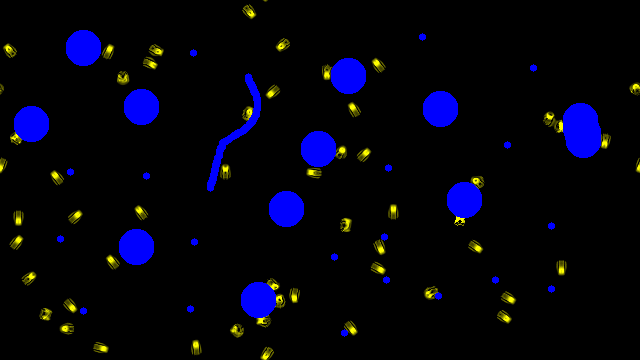
Multi creature

Maze
Zoomed in
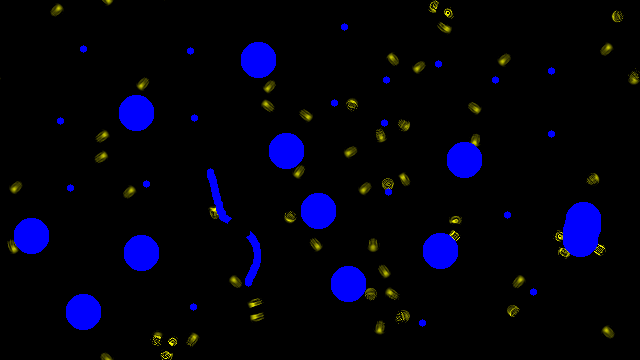
Multi creature

Maze

Zoomed in

Multi creature

Maze
Introduction: Connecting the dots between the Mechanistic and Enactivist views of Cognition.
Understanding what has led to the emergence of life, cognition and natural agency as we observe in living organisms is one of the major scientific quests in a variety of disciplines ranging from biology and chemistry to evolutionary science. The pragmatic complementary question, central in disciplines such as artificial life (ALife) and artificial intelligence (AI), is: can we engineer the necessary ingredients to discover forms of functional life and cognition as-it-could-be in an artificial substrata? With respect to this practical goal of building agents-as-they-could-be, key challenges are the modeling of an artificial environment environment: system that defines a notion of space, time, physical states and laws, the characterization of an agent embodiment embodiment: ensemble of norms and necessary conditions that define an agent as an autonomous unity we could separate from the rest and cognitive capacity/domain cognitive capacity/domain: ensemble of performances that an agent is able to realize and regulate in its environment , defined as the "domain of interactions in which a unity can engage without disintegration" within such an environment; and the finding of agents that (robustly) comply with those criteria. Depending on their focus of research, approaches in the literature can be divided into the mechanistic and the enactivist views. The mechanistic view already presupposes an agent embodiment and rather focuses on understanding how higher-level cognitive interactions can arise, typically seeking for agents capable of sensorimotor adaptivity sensorimotor adaptivity: sensory-motor coordination enabling agents to react to environmental perturbations, achieve repertoire of behavioral skills and adapt to unseen conditions. In the enactive view, "the question of the bodily constitution is conceptually prior to any particular functional account of a cognitive subsystem" . The prior conditions of individuality and self-maintenance are coined by enactivists as necessary for determining the agent's own existence and survival. Whereas the mechanistic considerations "jump over" the biological processes that enable organisms to survive (primitive forms of life/cognition), the enactivist considerations still "fall behind" on showcasing higher-level processes of sensorimotor adaptivity (advanced forms of life/cognition). Can future work in AI and ALife bridge the gap between those two frameworks?

In the mechanistic view, robots and other virtual agents are referred as "embodied" if they can ground their sensorimotor capabilities in the environment (the external world) via a physical interface (the body) allowing to experience the world directly (sensory inputs) and to act upon it (motor outputs) using internal input-output information processing (the brain). Embodiment here is opposed to the computational non-embodied perspective where internal representations, either symbolic-based in "good-old fashion AI" or neural-network-based in the "internet AI", are decoupled from the external world and lack situatedness . Yet, within the mechanistic modeling framework, it is not questioned what makes an agent an agent or even what makes a body a body : one assumes there is already a body interacting with the environment through predefined sensors and actuators. The agent individuality is clear: it is a separate unity (yellow box on the right figure) whose states and dynamics can be clearly distinguished from the states and dynamics of the rest of the environment. The agent self-maintenance is often not a problem as the agent body does not change over time except for rare cases of real world or artificially-induced degradations (e.g. robot damages, battery/energy level), and only the brain (white box on the right figure) adjusts to the environment. A more central question within that framework is the agent sensorimotor adaptivity: how to find agents capable of a repertoire of sensorimotor behaviors/skills such as locomotion, object manipulation or tool use and capable of adapting the learned behaviors to unseen environmental conditions ? To address that question in practice, a common methodology is the generation of a distribution of environments (tasks and rewards) to train the agent's brain to master and generalize those tasks, typically with learning approaches such as deep reinforcement learning. Whereas the focus is at the agent behavioral level, it remains open to criticism why the agent behavior should be instantiated in the brain in the first place, and why not in the body or even in the external world.
The clear body/brain/environment distinction of the mechanistic framework bears little resemblances with biological examples of brainless organisms using their body both for sensing and computing the decision. Plants move to get more sun, slime molds use mechanical cues of their environment to choose in which direction to expand , and swarm of bacterias can make group decisions to avoid a wall of antibiotics , while there is no clear notion of a "brain" in these living forms. Pfeifer and colleagues introduced the concept of morphological computation, arguing that all physical processes of the body (not only electrical circuitry in the brain but also morphological growth and body reconfiguration) are integral parts of cognition, and can achieve advanced forms of computation without a "brain". A famous example of (artificial) morphological computation is the passive bipedal walker which manages sensorimotor coordination and life-like locomotion behavior by simply exploiting the natural dynamics of the robot mechanical system.

There is no predefined notion of agent embodiment, instead it is considered that the body of the agent must come to existence through the coordination of the low-level elements and must operate under precarious conditions
The enactive view on embodiment however is rooted in the bottom-up organizational principles of living organisms in the biological world. The modeling framework typically uses tools from dynamical and complex systems theory where an artificial system (the environment) is made of low-level elements of matter \(\{a_i\}\) (called atoms, molecules or cells) described by their inner states (e.g. energy level) and locally interacting via physics-like rules (flow of matter and energy within the elements). There is no predefined notion of agent embodiment, instead it is considered that the body of the agent must come to existence through the coordination of the low-level elements and must operate under precarious conditions precarious conditions : the idea that bodies are constantly subjected to disruptions and breakdowns . Within that modeling framework, the condition of individuality is the ability of a self-organizing structure (subpart of the environment) to preserve and propagate some spatiotemporal unity , making it a distinguishable coherent entity in the domain in which it exists (called an autopoietic system in ). The condition of self-maintenance is the capacity of a self-organizing structure to modify its internal and interactive exchanges of matter and energy with the rest of the environment (action) when facing external changes in the states or rules of the dynamical system (perturbations) for maintaining its integrity (goal). Interestingly, this "autonomy of an autopoietic system constitutes its minimal cognition" .
Whereas both the mechanistic and the enactivist framework agree on agents as entities with some form of goal-directedness and action response to external perturbations, we can see how the characterization of agents in self-organizing systems is non-intuitive and very challenging in practice. Some recent works have proposed rigorous quantitative measures of individuality based on information theory tools . Other works from R.D. Beer attempted to formalize the characterization of the self-maintenance/cognitive domain of a spatio-temporal structure (such as a glider and other patterns in the game of life or a protocell model ) by enumerating the reactions to all possible perturbations that such structure can receive from its immediate environment. However, the practical application of those tools to identify forms of agency has so far been limited to toy models with small state grids and simple dynamics, as their algorithmic implementation requires exhaustive search and difficulty scales to more complex dynamical systems. Certainly due to those practical challenges, the higher-level questions of what makes an agent sensorimotor and adaptive and how such entities emerge in the enactivist framework remains, to our knowledge, poorly addressed in the literature.
Is it possible to find environments in which a subpart could exist/emerge and be called a "sensorimotor agent"?
In the work presented here, following the enactivist modeling framework, we initially only assume environments made of atomic elements and physical laws and try to answer the following scientific question: is it possible to find environments in which a subpart could exist/emerge and be called a "sensorimotor agent"? To do so, we use a continuous cellular automaton, called Lenia , as our artificial "world". At the difference of previous work in Lenia and CA in general, our methodological contributions to efficiently foster the emergence of robust sensorimotor agents within the search process integrate (i) a bi-level optimisation method based on gradient descent and curriculum-driven goal exploration and (ii) controllable functional constraints and opportunities in the environment by specifying (subparts of) the environmental dynamics. The blogpost is organized as follows.
In the first section, we explain how we made the Lenia framework as differentiable-friendly as possible in order to efficiently search for CA rules. The transition toward differentiable dynamics was recently proposed in the context of cellular automata or so-called neural CA (NCA). By unrolling the dynamics of the NCA over time and backpropagating through it, the use of deep-learning and differentiable programming tools allowed to efficiently find CA rules leading to complex patterns. Different training losses such as image , style-content and classification losses have been proposed. Inspired by a more traditional (non-embodied) deep learning framework, they have shown how complex pattern-generation (morphogenesis) and computation (self-classifying) processes could emerge in those systems. However, the use of such tools to efficiently search the parameterizations leading to the emergence of "sensorimotor agents" remains an unexplored research direction to date.
In the second section, we propose a method based on gradient descent and curriculum learning combined within an intrinsically-motivated goal exploration process (IMGEP IMGEP: algorithmic process that aims to discover a diversity of behaviours in a dynamical system. Itgenerates a sequence of experiments to explore the parameters of a dynamical system by targeting a diversity of self-generated goals . Here we use a population-based version and introduce two novel elements compared to previous papers: the use of gradient descent for local optimization and the ability to handle stochasticity in the dynamical system., an efficient form of diversity search algorithms that can be combined with gradient descent) to automatically search parameters of the CA rule that can self-organize spatially localized spatially-localized pattern: a pattern existing within some (fuzzy) boundary i.e. with a limited range in space as opposed to patterns with unbounded growth and moving patterns moving pattern: a spatially-localized pattern that move and propagate information in space within Lenia. While many complex behaviors have already been observed in Lenia, among which some could qualify as sensorimotor behaviors as illustrated in the side video, they have so far been discovered "by chance" as the result of time-consuming manual search or with simple evolutionary algorithms. In this work, we define an outer exploratory loop (generation of training goal/loss) and an inner optimization loop (goal-conditioned policy) that allow us to automatically learn the CA rules leading to the systematic emergence of basic sensorimotor structures.
In the third section, we explain how our environment's physical rules can integrate both predetermined specific properties and learnable properties. That "trick" to control subparts of the environmental physics allows us to build a curriculum of tasks for optimizing the learnable part of the environment, in which we are searching parameters that could self-organize sensorimotor agents robust to stochastic variations in the environmental constraints.Environment-design allows us, by shaping the search process, to discover more advanced forms of sensorimotor capabilities such as self-maintenance and adaptivity to the surroundings.
Finally in the last section, we investigate the (zero-shot) generalization of the discovered sensorimotor agents to several out-of-distribution perturbations that were not encountered during training. Impressively, even though the agents still fail to preserve their integrity in certain configurations, they show very strong robustness to most of the tested variations. The agents are able to navigate in unseen and harder environmental configurations while self-maintaining their individuality. Not only the agents are able to recover their individuality when subjected to external perturbations but also when subjected to internal perturbations: they resist variations of the morphogenetic processes such that less frequent cell updates, quite drastic changes of scales as well as changes of initializations. Furthermore, when tested in a multi-entity initialization and despite having been trained alone, not only the agents are able to preserve their individuality but they show forms of coordinated interactions (attractiveness and reproduction), interactions that have been coined as communicative interactions communicative interactions: "entity-entity perturbations that serve to orient entities within their respective cognitive domains to new possibilities for action" .
Searching for rules at the cell-level in order to give rise to higher-level cognitive processes at the level of the organism and at the
level of the group of organisms opens many exciting opportunities to the development of embodied approaches in AI in general.
Our results suggest that, contrary to the (still predominant) mechanistic view on embodiment, biologically-inspired enactive embodiment could pave the way toward agents with strong coherence and generalization to out-of-distribution changes, mimicking the remarkable robustness of living systems to maintain specific functions despite environmental and body perturbations . Searching for rules at the cell-level in order to give rise to higher-level cognitive processes at the level of the organism and at the level of the group of organisms opens many exciting opportunities to the development of embodied approaches in AI in general.
The system
Cellular automata are, in their classic form, a grid of "cells" \( A = \{ a_x \} \) that evolve through time \( A^{t=1} \rightarrow \dots \rightarrow A^{t=T} \) via local "physics-like" laws. More precisely, the cells sequentially update their state based on the states of their neighbours: \( a_x^{t+1}= f(a_x^t,\mathcal{N}(a_x^t))\), where \( x \in \mathcal{X}\) is the position of the cell on the grid, \(a_x \) is the state of the cell, and \(\mathcal{N}(a_x^t)\) is the neighbourhood of the cell. The dynamic of the CA is thus entirely defined by the initialization \( A^{t=1} \) (initial state of the cells in the grid) and the update rule \( f \) (how a cell updates based on its neighbours). But predicting their long term behavior is a difficult challenge even for simple ones due to their chaotic dynamics.
SLP

Moving pattern

The Game of Life is one example of cellular automaton with binary states where cells can either be dead (\(a_x=0\)) or alive (\(a_x=1\)). Despite its very simple rule \(f\), very complex structures can emerge in it. One main type of pattern studied in the game of life is stable spatially localized patterns (SLP) : patterns with a kind of spatial boundary that separates the unity from the rest. The subcategory of moving patterns, SLP that periodically get back to their state after some timesteps but shifted in space, is of particular interest. The well-known glider, as shown on the right, was even proposed as a computational model of an autopoietic system .
The cellular automaton we study in this work is Lenia which has the particularity of having continuous C-dimensional states (\(a_x \in [0,1]^C\)). To be more precise, Lenia is a class of cellular automata in which each instance is a Cellular Automaton (CA). A CA instance is defined by a set of parameters \( \theta \) that condition its "physics" such that the update rule \(f\) is parametrized: \( a_x^{t+1}= f_{\theta}(a_x^t,\mathcal{N}(a_x^t))\). For example, the Game of Life can be seen as a particular instance in Lenia. Having these update rules parametrized allows the search for CA environments with rules which can lead to the emergence of interesting patterns, including SLP and moving ones. Contrary to the perfectly stable or periodically oscillating patterns in the game of life, it is very hard to know if a SLP in Lenia will not explode or vanish after a long period of time on account of tiny drift changes in its continuous states.
A wide variety of complex patterns has been found in Lenia, using a combination of hand made exploration/mutation and evolutionary algorithm or exploratory algorithm . The work from focused a lot on spatially localized patterns and especially moving ones.
Creatures obtained by hand made random exploration
Creatures at the top areorbiums in Lenia .
Videos at the bottom are from Bert Chan's twitter, found by handmade random exploration :
left, right
Finding creatures like these can take time (and expert knowledge) especially for more complicated ones.
You can find a library of creatures found in the first version of Lenia () at this link.
The moving creatures found are long term stable and can have interesting interactions with each other but some as the orbium (which you can find on the 2 upper videos) are not very robust for example here with collision between each other. Other more complex creatures (as shown in the two bottom videos) seem to resist collision better and to be able to sense the other creatures. These creatures show sensorimotor capabilities as they change direction in response to interaction with other creatures.
However, all of the previous methods use only random mutations and manual tuning to find these patterns, which can be computationally heavy especially to find very specific functionalities or in high dimensional parameter space. This motivates our choice to make Lenia differentiable, which then allows us to take advantage of the differentiability to find, in a more efficient and systematic way, the parameters leading to the emergence of agents with similar types of behaviors .
In this section, we first explain in more detail the model in Lenia and present how we made parts of the Lenia model differentiable.
Lenia
In Lenia , the system is composed of several communicating grids \( A=\{ A_c\}\) which we call channels. The above video illustrates Lenia "physics" in a 2-channel example ( \(A_1\) is colored in yellow and \( A_2 \) in blue). In each of these grids, every cell/pixel can take any value between 0 and 1. Cells at 0 are considered dead while others are alive. As shown in the video, the channels are updated in parallel according to their own physics rule. Intuitively, we can see channels as the domain of existence of a certain type of cell. Each type of cell has its own physics : it has its own way to interact with other cells of its type (intra-channel influence) and also its own way to interact with cells of other types (cross-channel influence).
The update of a cell \( a_{x,c}\) at position \(x\) in channel \(c\) can be decomposed in three steps. First the cell senses its neighbourhood in some other channels (its neighbourhood in its channel, with cells of the same type but also in other channels with other types of cells) through convolution kernels which are filters \(K_k\) of different shapes and sizes. Second, the cell converts this sensing into an update (whether positive or negative growth or neutral) through growth functions \(G_k\) associated with the kernels. Finally, the cell modifies its state by summing the scalars obtained after the growth functions and adding it to its current state. After the update of every rule has been applied, the state is clipped between 0 and 1. Each (kernel,growth function) couple is associated to the source channel \(c_s\) it senses, and to the target channel \(c_t\) it updates. A couple (kernel,growth function) characterizes a rule on how a type of cell \(c_t\) reacts to its neighbourhood of cells of type \(c_s\). Note that \(c_s\) and \(c_t\) could be the same, which correspond to interaction of cells of the same type (intra-channel influence). Note also that we can have several rules characterizing the interaction between \(c_s\) and \(c_t\), i.e. \(n(c_s \rightarrow c_t)\) (kernel,growth function) couples.
A local update in the grid is summarized with the following formula:
$$a_x^{t+1}=f(a_x^t, \mathcal{N}(a_x^t)) = \begin{bmatrix} a^t_{x,c_0} + \sum_{c_s=0}^C \sum_{k=0}^{n(c_s \rightarrow c_0)-1} G^k_{c_s \rightarrow c_0} ( K^k_{c_s \rightarrow c_0} (a^t_{x,c_0}, \mathcal{N}_{c_0}(a^t_x))) \\.\\.\\.\\a^t_{x,c_C} + \sum_{c_s=0}^C \sum_{k=0}^{n(c_s \rightarrow c_C)-1} G^k_{c_s \rightarrow c_C} ( K^k_{c_s \rightarrow c_C} (a^t_{x,c_C}, \mathcal{N}_{c_C}(a^t_x)))\end{bmatrix} $$
For each rule, the shape of the (kernel, growth function) is parametrized. We are thus able to "tune" the physics of the cells and of their interactions by changing the kernels shape (how the cells perceive their neighborhood) as well as the growth function shape (how the cells react to this perception).
However, finding interesting parameters leading to the emergence of localized patterns or even moving one is not easy. For example here is a random search of 100 trials (with 1 channel and 10 rules) gives only 3-5 SLP and no moving creature. Even with more advanced diversity-driven exploration searches, moving creatures are hard to find . This motivates our choice to use gradient descent in order to learn these parameters.
Random exploration of the parameter space rarely results in moving creature.
Each 100 squares are random parameters trials (each 1 channel and 10 rules so \(\sim \) 130 parameters for all the rules of a square). The parameters
control the local rules of interaction between cells, by changing the kernel shape (how a cell senses) and the growth function (how this sensing
is converted into growth).
Differentiable Lenia
Due to the locality and recurrence of the update rule, there is a close relationship between cellular automata and recurrent convolutional networks . In fact, we can see a rollout in Lenia as applying a recurrent neural network to an initial state. If (some of) the network parameters are differentiable, backpropagation can be done by "unfolding" the Lenia rollout and applying a loss at certain time step(s) like in .
However, in the classic version of Lenia , the shape of the kernels are not totally differentiable and not very flexible. To allow easier optimization of the Lenia system, we introduce some changes to the kernel parametrization. You can find these changes in the Differentiable Lenia Shift section of the appendix. However even doing so, differentiating through Lenia can be difficult because the gradient must backpropagate through several steps (which moreover have their result clipped between 0 and 1) without vanishing. We should thus limit ourselves to a few iterations when training: in our experiments the loss is applied after 50 steps in Lenia.
How to discover spatially localized and moving agents in Lenia ?
In this section, we propose tools based on gradient descent and curriculum learning to learn the CA parameters leading to the emergence of moving creatures. Finding gliders-like creatures will be the basis on which we'll build the method leading to the emergence of sensorimotor capabilities within the Lenia dynamics in the next section.
In this study, we learn to develop morphology and motricity at the same time. The CA rule will both be applied to grow
the creature from an initial state and be the "physics" that makes it move.
Note that moving creatures in cellular automaton differ from other types of movement like motors, muscle contraction or soft robot . CAs operate on a fixed grid and therefore moving necessarily requires patterns growing at the front and dying at the back. This should imply that creatures that move are more fragile because they are in a fragile equilibrium between growth (to move forward) and dying (because otherwise we would have infinite growth). In this study, we learn to develop morphology and motricity at the same time. The CA rule will both be applied to grow the creature from an initial state and be the "physics" that makes it move.
In this section, we only work with 1 channel (only 1 type of cells interacting). In this channel we want to learn the several rules (parameters of the kernel+growth functions encoding the interactions of those cells within the channel) that will result in the emergence of moving creatures when given the proper initialization. At the same time we also aim to learn an initialization that will be adapted to these rules i.e. lead to the emergence of the creature.
We start by randomly initializing the parameters and initialization until we get a localized pattern, meaning it doesn't spread to the whole grid and doesn't die . This obtained pattern will most of the time stay at the same position. What we want is to change the parameters and initialization such that this pattern ends further in the grid, meaning that it survived and stayed localized but moved to a different location in a few timesteps. Because our system is differentiable, we're able to backpropagate through the timesteps by "unfolding" the roll-out. We therefore need a loss applied on the roll-out which will encourage movement to a new position z.

Schematic view of optimization step
Differentiable Lenia allows to optimize the CA parameters such that its dynamics converges
towards a target pattern. Here the figure shows optimization of the system with MSE error between target image and system state at last timestep.
Different training losses could be envisaged and applied at intermediate time steps depending on the dynamical
properties one aim to emerge in the system
.
Target image with MSE error applied at the last timestep of a rollout seems effective to learn CA rule leading to a certain pattern . And the fact that it's a very informative loss, thus helping with vanishing gradient problem, made us choose this loss for our problem over other losses such as maximizing the coordinate of the center of mass. We apply the MSE loss between the pattern at the last timestep of the roll out and a target shape put at a target location further in the grid.
The first target shape we tried was a single disk with the idea of getting a spatially localized agent contained within the disk as the target shape is finite. However, after seeing that the robust creature obtained seemed to have a "core" and a shallow envelope, we informally chose to move to two superposed discs, a large shallow one with a thick smaller one on top. The resulting target shape has the formula \(0.1*(R<1)+0.8*(R<0.5)\). We chose on purpose to have the sum to be smaller than 1 to avoid killing the gradient due to the clip operation.
Despite the choice of the target shape, the choice of the target location is crucial for the success of the optimization. Simply putting a target shape far from initialization and optimizing towards it does not work most of the time. In fact, it works only when the target is not too far ( more precisely overlaps a little bit) from where the creature ended before optimization. This comes from the fact that cells at 0 do not give gradients as we clip between 0 and 1 and so, for example, if at last timestep the target shape is on an area where the cell states are clipped at 0 no gradient will be propagated. Moreover, as the system is complex/chaotic, the optimization landscape will be very hard and changing some parameters too much can easily break the dynamic leading to completely different outcomes (loosing all the progress and making further optimization very hard). And so putting the target at a close position should lead to easier optimization landscape as well as more gradient information (because more non clipped pixel will overlap the target), leading to better optimization steps with less chances to diverge. To use these small steps, we propose to use curriculum learning exploiting the fact that we can shape optimization to aim for near-enough (and increasingly further) target shapes.

Result of Optimization step
Red : target, yellow : initialization and green : agent at last timestep.
Left to right is one optimization step. The agent learns to go a little bit further in the same amount of time.
.
Curriculum-driven goal exploration process
The effectiveness of curriculum with complex tasks has already been shown in Wang et al. where a teacher agent was created to design increasingly complex tasks for another learning agent, such that the learning tasks were neither too hard nor too easy. Recent work by Variengien et al. showed the need of curriculum to stabilize learning and avoid local minima in complex self organizing systems .
However, defining a learning curriculum (in our case defining how far and in which direction the target should be pushed at each optimization phase) is not trivial. In fact, some locations can lead to a hard optimization landscape (e.g. with a danger to get trapped in local minima or to diverge) while some other locations by luck can make the optimization easy. And these "easy" targets would change for every random initialization.
To tackle these challenges, we propose to rely on intrinsically-motivated goal exploration processes (IMGEPs), an algorithmic process which was shown successful at generating a learning curriculum for complex exploration spaces in robotics and which has already been used in Lenia as a diversity search tool . The general idea of IMGEP is to iteratively set new goals to achieve and for each of these goals try to learn a policy (here a policy is simply an initial state and the CA rule) that would suit this goal. To do so, an IMGEP integrates several key mechanisms: a goal-sampling policy (that decides how to sample interesting new goals, for example based on intrinsic reward), a goal-achievement criterion (that tracks the progress on a goal), and a goal-achievement policy (that optimizes toward a target goal). Importantly, an IMGEP can reuse the knowledge acquired on other goals to learn new goals or attain them more quickly.

IMGEP Step
Hover over gray areas to show the details of the step.
An IMGEP is an algorithmic process that allows to sample new goals and try to achieve them. The IMGEP process reuses knowledge from the previous
trials. In our case, we use IMGEP as it allows to automatically build a curriculum by randomly trying new goals.
In our case, the goal space is simply a 2-dimensional vector space representing the position of the center of mass of the creature. Hence, a policy in Lenia (controlling the CA initialization and rules) achieves a target goal when it produces a creature whose position at the last timestep (here t=50) is within an accepted range from the target one. While there exist many goal-sampling strategies in the IMGEP literature, we use here a simple version that randomly samples positions in the grid but that biases the sampling both toward one edge of the grid in order to obtain moving creatures and taking care that the sampled goals are not too far from already-attained positions. To attain a new target position/goal, the goal-achievement policy relies on (i) the history of previously-tried policies to select the parameters that performed best (achieved the closest position); and (ii) an inner loop that uses gradient descent with MSE error between the selected policy's last state and the target shape centered at the target goal. Therefore, there are two loops, one outer setting the goals and one inner that applies several steps of gradient descent toward this goal. The overall method can be summarized as such:
Perform random policies in Lenia saving the obtained (parameters,reached goal) tuples in history \(\mathcal{H} = (p_i,rg_i)_{i=1,..s}\)
Loop (number of IMGEP step)
Sample target position/goal (not too far from reached positions in the history \(\mathcal{H} \) )
Select, from the history , the parameters that achieved the closest position/goal
Initialize the system with those parameters
Loop (number of optimisation steps)
Run lenia
Gradient descent toward the target shape at target position to optimize the parameters
Initialize the system with those optimized parameters
Run lenia one more time to see what is the position (i.e. goal) achieved
If the creature died or exploded, don't save
Else, add to history the parameters resulting from optimization and the outcome/goal reached \(\mathcal{H} =\mathcal{H} \cup (p^\star,rg )\)
An advantage of IMGEPs is that the information collected when a policy "fails", e.g. reaching a position far from the selected target, can be useful later on for reaching other positions: it might still make a small improvement or it might go in a completely different area which we might want to explore. The fact that we don't always select the last checkpoint as in classic curriculum learning also allows us to have different "lineages" which may help to avoid being stuck in local minima or in an optimization area where the optimization can easily diverge.
Moving creatures obtained
Robustness of learned moving creatures over longer time spans than in the training process.
Each square is the result of 1 trial of the method. The video on the left displays successes of the method
where the creatures obtained are long term stable. The video on the right displays trials where the creatures obtained die few steps after the
number of timesteps it has been trained on. The last creature on the right
tries as much as possible to fit the target at last seen timestep resulting in a death right after.
The method proposed above gives us a set of rules and an initialization in Lenia that lead to the emergence of a moving creature. The obtained rules and initialization are different every time we run the search as the method's initialization (first line in the pseudocode) is random. This results in different creatures emerging with every set of obtained rules (different seeds of the method). Interestingly, some of the emerged creatures are long term stable (their shape is kept stable) while others may become unstable after a few timesteps. In fact as the creature is only trained for 50 timesteps, when running for longer, the creature can have unpredictable behaviors. Seeing that the majority of creatures that emerge from training are long term stable (8 over 10 trials with initialization selection, see appendix for more info on initialization selection), whereas it is not specified/penalized in the training loss, is a first hint of the generalization capabilities of self-organizing agents.
Results of successive outer (top) and inner (bottom) optimization steps in practice in 2 different runs
This figure shows how the bi-level optimization (an inner loop inside of an outer loop) progressively evolves moving creatures. For each run, the upper-left video corresponds to the creature obtained after initialization of the parameters (before optimization), which is not able to move at all. After several outer steps (shown at the top and separated by blue lines), we can see how the evolved creatures improve their behavior, with the upper-right one (at the end of the bi-level optimization) reaching quickly the edge of the grid. At the bottom, a "zoom" (represented by the red lines)
on the first outer step (between first and second top videos)
shows in more details the successive small improvements made by the inner loop
(gradient steps) during first outer step. Each inner step slightly improves the creature by making it go a little further. At the end of
these inner steps, we get the result of the first outer step (second top video).
Can we learn robust creatures with sensorimotor capabilities ?
When we talk about sensorimotor capability, we expect agents that are able to robustly perform goals
(such as moving toward the opposite edge of the CA grid) under a variety of environmental conditions, involving
the processes of sensing the environment and acting upon it.
In the previous section, we have shown how to learn rules in Lenia leading to the emergence of agents with moving capacity. However this was done in a neutral environment, where agents did not have to cope with any external perturbations. When we talk about sensorimotor capability, we expect agents that are able to robustly perform goals (such as moving toward the opposite edge of the CA grid) under a variety of environmental conditions, involving the processes of sensing the environment and acting upon it. To find sensorimotor capable agents, we want to train them on a variety of tasks that are not only specified by a goal (2D position on the CA grid) but also by an environmental configuration (everything that is "outside" of the agent and that challenges goal achievement). The effectiveness of training agents on a curriculum of tasks (curriculum of goals but also curriculum of environmental configurations per goal) has been shown to foster the emergence of generally capable agents . However, environment design and task generation is not trivial within the enactivist CA paradigm. Contrary to works where there are clear distinctions between agent/environment and sensors/actuators, in our framework there is only an environment made of low-level particles and a sensorimotor macro-behavior can only emerge from the application of local rules. Environmental perturbations must be specified as a controllable subpart of the particle rules/physics we want to impose in our system, while the remaining rules/physics are left free and learnable as the ones leading to interesting behaviors like emergence of sensorimotor agency.
In this work, we focus on modeling obstacles in the environment physics and propose to probe the agent sensorimotor capability as its performance to move forward under a variety of obstacle configurations. This section explains how we model the agent-obstacle interactions in Lenia and how our training method integrates the generation of a curriculum of stochastic goals and obstacle configurations, leading to the emergence of sensorimotor capable creatures.
Modeling agent-environment interactions in Lenia, the example of obstacles.

Formulas
Update step in our Lenia System with obstacle channel
The obstacle channel is another parallel grid which allows to put obstacles in the environment by putting
some of the pixels of this grid to 1. These obstacles will have a direct impact (through a fixed local rule) on the learnable channel
as it will prevent any growth of the creature where obstacles are present.
You can hover on the Formulas button to see the corresponding Lenia's equations.
The multi-channel aspect of Lenia allows the implementation of different types of cells/particles. To implement obstacles in Lenia we added a separate "obstacle" channel with a kernel going from this channel to the learnable "creature" channel. This kernel triggers a severe negative growth in the pixels of the learnable channel where there are obstacles but has no impact on other pixels where there are no obstacles (very localized kernel). This way we prevent any growth in the pixels of the learnable channel where there are obstacles.
a ) Orbium (glider like in Lenia obtained by hand made mutation) dies from perturbation by obstacles
b) In the creatures found by handmade random exploration, some die from perturbation by the obstacle while some
by luck are able to resist these perturbations.
c) Creatures obtained in the previous section
(which were trained to move forward without external perturbations) die from collision with obstacles.
d) Some creatures obtained in the previous section resist some collisions (left) but often die from other collisions (right). The
creature is the same in both videos.
The learnable channel cells can only sense the obstacles through the changes/deformations it implies on it or its neighbours. In fact, as the only kernel that goes from the obstacle channel to the learnable channel is localized, if a macro agent emerges it has to "touch" the obstacle to sense it. To be precise the agent can only sense an obstacle because its interaction with the obstacle will perturb its own configuration and dynamics (i.e. its shape and the interaction between the cells constituting it). This is similar to experiments with swarming bacteria , where the swarm agent must learn to collectively avoid antibiotic zones (externally-added obstacles) where the bacteria can't live.
Additionally, we impose the obstacles to stay still, meaning that there is no rule that goes toward
(and hence no update of) the obstacle channel
. As such, an update step in the final system is summarized in the
above figure
with the channel 1 being the learnable channel while the channel 2 is the obstacle channel.
To grasp the impact of the new obstacle channel and physics, we then tested how the previously-found moving creatures react to this environment.
The creatures found by hand in Lenia are not very robust to this new environment physics. A glider type of creature that was found in 1-channel Lenia dies from most collisions with external obstacles (figure a). Another multi-channel creature (figure b left) dies from special collisions with the wall. Only one multi-kernel creature was able to sense the wall and resist perturbation, but even this required us to manually slow down Lenia's time (parameter T) so that the creature can make smaller updates. And even then, the creature movements are kind of erratic.
Similarly, the moving creatures obtained with gradient descent and curriculum in the previous section do not display much robustness to collision with obstacles (figure c): only few by luck already have some level of robustness (figure d). This motivated the need for training methods which, given this environmental physics in the CA paradigm, are able to learn the parameters leading to the emergence of agency and sensorimotor capabilities with better resilience to perturbations.
Training method with stochastic environmental perturbations

Two different configurations of obstacles during training
The inner optimization samples diverse positions of obstacles allowing generalization as it induces, during training,
different perturbations on the agents.
For instance this figure displays 2 examples of sampled configurations (blue circles positions) and we can see that
the perturbations on the creature structure/morphology are totally different in left and right figure.
To learn the rules leading to the emergence of a creature that would resist and avoid various obstacles in its environment, we simply introduce (randomly generated) obstacle configurations within the training process, as shown in red in the training pseudocode. This way, the inner loop (goal-directed gradient descent) becomes stochastic gradient descent with the stochasticity coming from the sampling of the obstacles. The learning process will thus encounter a lot of different obstacle configurations and may find a general behavior. In practice, we only put obstacles in half the lattice grid. This way, as shown in the above figure, the first half of the grid is free from obstacles which allows to first learn a creature that is able to move without any perturbation, as it was done in the previous section. Then, as we push the target further and further, the creature starts to encounter obstacles. And the deeper the target position is, the more it encounters obstacles and so the more robust it should be. The curriculum is made by going further and further because the further you go the more you will have to resist obstacles. In the IMGEP, at the end of each goal-directed inner optimization, the goal achievement is measured as the distance between the target position and the average position attained on different other random configurations of obstacles.
Perform random policies in Lenia saving the obtained (parameters, reached goal) tuples in history \(\mathcal{H} = (p_i,rg_i)_{i=1,..s}\)
Loop (number of IMGEP step)
Sample target position/goal(not too far from reached positions in the history \(\mathcal{H} \) )
Select, from the history , the parameters that achieved the closest position/goal
Initialize the system with those parameters
Loop (number of optimisation steps)
Sample random obstacles
Run lenia
Gradient descent toward the target shape at target position to optimize the parameters
Initialize the system with those optimized parameters
See what is the mean position(ie goal) achieved
over several random obstacles runs
Loop (number of random run)
Sample random obstacles
Run lenia
Add reached goal to the mean
If the creature died or exploded during one of the tests, don't save
Else, add to history the parameters resulting from optimization and the mean outcome/goal
reached \(\mathcal{H} =\mathcal{H} \cup (p^\star,rg )\)
The success of the method to produce rules that lead to the emergence of sensorimotor agents highly depends on the IMGEP initialization (first line of the pseudocode). We refer to the overcoming "bad initialization" section of the appendix for more information on how we solve this problem. Additional experimental details are also provided in the appendix.
Robust moving creatures obtained
From the method, we obtain a wide variety of creatures that seem to easily travel through random configurations of obstacles like the ones they saw during training. Over 10 trials of the method with initialization selection (see appendix for more info on initialization selection), 7 succeeded leading to such creatures. You can find the failure cases in the failures cases section of the appendix.
The obtained emerging creatures are robust to perturbation by obstacles
The creatures were obtained by adding obstacle perturbations during training.
This robustness was not observed when the creature was trained to go forward without any perturbation as shown in figure c at the
beginning of the section.
The obstacle configurations are totally random and have not been seen during training.
In the 3 first videos, yellow corresponds to the learnable channel (where we want the creature to emerge), and blue to obstacles in the system.
In the last video, the learnable channel has a custom colormap allowing to see
more easily the wide range of continuous states in the creature while the obstacles are
in black.
How well do the creatures obtained generalize ?
In this section, we investigate the generalization of the discovered sensorimotor agents to several out-of-distribution perturbations that were not encountered during training. While the creatures were trained on a diversity of obstacle positions (but with fixed number, shape and size), we can imagine a much larger and challenging set of evaluation tasks to assess the agent's general sensorimotor capabilities. Below we show a sample of such possible test tasks, while many more could be envisaged. To better display the versatility of some of the creatures obtained, we keep the same creature for all the demo below except stated otherwise. In the first part of this section, we look at the capabilities of the obtained creatures "alone", without paying attention to creature-creature interactions. In the second part, we test the capabilities of the obtained creatures to interact with each other in the multi creature setting.
Single creature setting
ARE THE CREATURE LONG TERM STABLE ?
Even if we can not know if the creature is indefinitely stable, we can test for a reasonable number of timesteps. The result is that the successful creatures that were obtained with IMGEP with obstacles seem stable for 2000 timesteps while they have only been trained to be stable for 50 timesteps. This might be because as it learned to be robust to deformation it has learned a strong preservation of the structure to prevent any explosion or dying when perturbed a little bit. And so when there is no perturbation this layer of "security" strongly preserves the structure. However, training a creature only for movement (without obstacles so no perturbation during training) sometimes led to non long term stable creatures. This is similar to what has been observed in where training to grow a creature from the same initialization (a pixel) led to patterns that were not long term stable. But adding incomplete/perturbed patterns as initialization to learn to recover from them led to long term stability by making the target shape a stronger attractor.
ARE THE CREATURES ROBUST TO NEW OBSTACLES ?
The resulting creatures are very robust to wall perturbations and able to navigate in difficult environments with various unseen configurations of obstacles including vertical walls (see interactive demo). One very surprising emerging behavior is that the creature is sometimes able to come out of dead ends showing how well this technique generalizes. There are still some failure cases, with creatures obtained that can get unstable after some perturbations, but the creatures are most of the time robust to a lot of different obstacles. The generalization is due to the large diversity of obstacles encountered by the creature during the learning. Moreover as it learns to go further, the creature has to learn to collide with several obstacles one after the other and so be able to recover fast but also still be able to resist/sense a second obstacle while not having fully recovered.
ARE THE CREATURES ROBUST TO MOVING OBSTACLES ?
We can make a harder out of distribution environment by adding movement to the obstacles. For example we can do a bullet like environment where the tiny wall disks are shifted by a few pixels at every step. The creature seems quite resilient to this kind of perturbation even if we can see that a well placed perturbation can kill the creature. However, this kind of environment differs a lot from what the creature has been trained on and therefore shows how much the creature learned to quickly recover from perturbations, even unseen ones.
ARE THE CREATURE ROBUST TO ASYNCHRONOUS UPDATE ?
As done in , we can relax the assumption of synchronous update (which assumes a global clock) by adding a stochastic update. By applying a mutation mask on each cell, which is toggled on average 50% of the time, we get partial asynchronous updates. The creature we obtained with the previous training with synchronous updates seems to behave "normally" with stochastic updates. The creature is slowed a little bit but this is what we can expect as each cell is updated on average 50% of the time.
ARE THE CREATURE ROBUST TO CHANGE OF SCALE ?
The grid is the same size as above giving an idea of the scale change (kernel radius*0.4)
We can change the scale of the creature by changing the radius of the kernels as well as the size of the initialization square (with an approximate resize). This is a surprising generalization as it completely changes the number of cells constituting the macro entity. We can make much smaller creatures that therefore have less pixels to do the computation. This scale reduction has a limit but we can get pretty small creatures. The creatures still seem to be quite robust and be able to sense and react to their environment while having less space to compute. We can also do it the other way around, and have much bigger creatures that therefore have more space to compute (but also more cells to organize). Interestingly, evidence of multi-scale adaptivity is also something that can be observed in biological organisms .
ARE THE CREATURES ROBUST TO CHANGE OF INITIALIZATION ?
While the creature initialization has been learned with a lot of degree of liberty, we can look if the same creature can emerge from other (maybe simpler) initialization. This capacity to converge to the desired shape in spite of a different initialization can be found in nature, as shown in this work from Vandenberg et al. on morphogenesis in tadpoles with perturbed structures. This would show how the learned CA rule is prone to encode, grow and maintain a target shape. In fact, as the creature learned to recover from perturbed morphology, we can expect the shape to be a strong attractor thus letting more freedom on the initialization. Indeed, what we find in practice is that the creature can emerge from other initializations, especially as shown here from a circle with a gradient (need some asymmetry to initiate movement as the kernels are fully symmetric). Bigger initializations also lead to multiple creatures forming and separating from each other (see next section for more about individuality). However the robustness to initialization is far from being perfect as other initializations easily lead to death, like for example here a circle of inappropriate size.
Do the creatures react to body damages?
In order to navigate, the creature first needs to sense the wall through a deformation of the macro structure. Then after this deformation it has to make a collective "decision" on where to grow next and then move and regrow its shape. We can even do the deformation ourselves by suppressing a part of the creature, the result is that the creature is effectively changing direction as if an obstacle was present. This confirms that the perturbation of the macro structure is what leads to the direct change of direction. It's not clear looking at the kernels activity which ones (of the kernels) are responsible for these decisions if not all. How the decision is made remains a mystery. Moreover some cells don't even see the deformation because they're too far away, meaning that some messages from the one sensing it have to be transmitted.
Multi creature setting
By adding more initialization squares in the grid, we can add several macro creatures constituted by identical cells (with the same update rule) letting us observe multiple creatures . As pointed out by R.D. Beer , other entities are also part of the environment for the creature and can give rise to nice interactions. Maturana and Varela even refer to this kind of interaction as communication Communicative Domain: "a chain of interlocked interactions such that although the conduct of each organism in each interaction is internally determined by its autopoietic organization, this conduct is for the other organism a source of compensable deformations." . Note that the creature never encountered any other creature during its training and was always alone.
INDIVIDUALITY
For this creature displayed here, we had to tune by hand the kernel after the training in order to get individuality. But we sometimes obtain individuality directly from the training.
Some creatures obtained show strong individuality preservation. In fact, creatures go in non destructive interactions most of the time without merging, despite the fact that they're all made from identical cells. If individuality isn't obtained during training, we can tune the weight of the growth (especially the limiting growth one) to make the merge of two creatures harder. By increasing those limiting growth kernels, the repeal of two entities gets stronger and they will simply change direction. Individuality has also been observed in the "orbium" creature found by hand in Lenia for example, but it was much more fragile with a lot of collisions that led to destruction or explosion. It's interesting to notice that individuality can be obtained as a byproduct of training an agent alone. In fact our intuition is that by trying to prevent too much growth, it learned to prevent any living cell that would make it "too big", including in the multi creature case living cells from other creatures. Over the 10 random trials, 4 of them led to the emergence of creatures with strong individuality preservation.
ATTRACTION
If they are too far from each other no attraction.
One other type of interaction between two creatures of the same species (governed by the same update rule/physic) is creatures getting stuck together. The two creatures (here it's a different creature than the one shown above) seem to attract each other a little bit when they are close enough, leading to the two creatures stuck together going in the same direction. When they encounter an obstacle and separate briefly, their attraction reassembles them together. Even when they're stuck together, from a human point of view seeing this system, we can still see 2 distinct creatures. This type of behavior is studied in the game of life in with the notion of consensual domain.
REPRODUCTION
Another interesting interaction we observed during collision was "reproduction". In fact, for some collision, we could observe the birth of a 3rd entity. This kind of interaction seemed to happen when one of the two entities colliding was in a certain "mode" like when it just hit a wall. Our intuition is that when it hits a wall, it has to have a growth response in order to recover. And during this growth response if we add some perturbation of another entity it might separate this growth from the entity and then this separated mass from strong self-organization grows into a complete individual.
THEORETICAL FOUNDATIONS OF COGNITION
Cellular automata have been used as a testbed/showcase for theories on cognition, identity and life (like what are the necessary parts needed for "life" ?). The game of life was particularly studied and in particular the glider. In fact, to test the cognitive domain of a glider R.D.Beer looked at all the environmental perturbations a glider in the game of life can take without dying. Taking inspiration from those works, we tried to learn, using modern ML tools, rules of a cellular automaton leading to the emergence of a structure/an agent with the capability to resist a maximum of perturbations hence with cognition (according to Maturana and Varela) at a certain level.
On the other hand, Information theory can be used to define more clearly concepts such as individuality, agency and cognition by giving a measure of such concepts . However, those measures are often very hard to apply in practice to big complex systems such as cellular automata. This is even more the case for continuous cellular automata such as Lenia with often large grids, a lot of steps and large neighborhoods (so a lot of interconnected dependencies).
NEURAL CA
Neural cellular automata (NCA) use the flexibility and differentiability of neural networks to express and learn the update rule for a variety of tasks . NCA have been used to learn cells to grow and regenerate a desired shape in case of damage , self-organize in a texture , classify handwritten digit in a decentralized way , perform complex image segmentation tasks or even be the circuits computing the action from inputs in a task . Taking advantage of the shared local learning rules, NCA are able to perform complex tasks with very little number of parameters (few thousands) in comparison to current deep learning models. For comparison, the Lenia rule in this work only has 130 parameters and yet is able to produce relatively advanced sensorimotor-like behaviors. Another NCA study explores how we can perturb the cohesive communication between cells in order to change the behavior of the whole "entity", using adversarial attack either with transformation of some cell states or with rogue cells. More details comparing the NCA model with our Lenia system can be found in the appendix.
SWARM ROBOTICS
We can draw parallels with swarm robotics which dictates how several agents should sense and communicate locally in order to arrange themselves in the group and in their environment . Work in swarm robotics is inspired by nature (ants, bees, fish, birds etc) and covers various areas of navigation like collective exploration , Coordinated motion ,, or even Collective decision-making . In those works, the swarm is composed of entities that already have a quite high level of cognition. This differs from our work where the entities composing the agent (the pixels ) are more abstract and on a lower level of cognition. However, the multi agents setting we present in this work could be seen as a swarm of higher cognition agents.
VOXEL BASED SOFT ROBOTS
Voxel based soft robots are composed of several tiny blocks/entities glued together that can contract (actuator). The contractions are either automatic contractions or with independent controller in every block using feedback from the environment . Other studies on automatic contraction robots focused on shapeshift to recover from injury .
Works on soft robotics have focused on designing the morphology of soft robots using cellular automata as builders of the morphology, as well as responsible for regeneration . Whereas they separate building and regenerating into two different CA, our work learns a single global CA rule for everything (every function :building, moving, regenerating creatures and changing direction in response to perturbation ).
CO-EVOLVING THE MORPHOLOGY AND THE CONTROLLER
Evolving the morphology to find good (and diverse) morphology for a task (with the associated global controller) has been studied in . However, in those works the morphology is fixed during the simulation, which is not the case in our system.
Pathak et al worked on the dynamical self assemblies of simple entities in order to build a bigger modular agent able to move in space. In this work, each tiny entity (limb) has a motor and is capable of linking to other close entities (during simulation) leading to the assembly of complex morphologies during the simulation. Each limb is independent and acts using its own information as well as the information from its neighbors. Each entity (limb) in this work is at a "good" level of cognition with concrete action such as linking or contracting.
OPEN ENDED EXPLORATION
The application of intrinsically-motivated goal exploration processes for the automated discovery of self-organizing patterns in Lenia follows population-based IMGEP systems in but differs in the IMGEP objective (choice of the goal space that one aim to cover) and goal-achievement strategy (local goal-directed optimizer). More specifically, previous work aimed to explore as much as possible the system by targeting diverse goals in an unsupervisedly-learned goal space ; and even expanding the search in an open-ended manner toward diverse (possible types of) diversity representations with dynamic and modular goal spaces, which was called meta-diversity search . Here, we manually specified a goal achievement measure (distance to target position and target shape) where we see problem-solving as the emergence of localized, moving and resilient patterns. However, whereas previous work used a very basic nearest-neighbor goal-achievement strategy, our work relies on stochastic gradient descent for the local optimization of the (sensitive) parameters of the complex system, which has shown to be very powerful. While not a central contribution of our work, it is the first in the population-based IMGEP literature where gradient descent and stochasticity handling are used for local optimization in the dynamical system. In future work, it could be interesting to combine the two approaches for doing some quality-diversity search, e.g. aiming to find a diversity of creature morphologies that are all sensorimotor-performant in Lenia.
Discussion
The computation of decision is done at the macro (group) level, showing how a group of simple identical entities can make "decision" and "sense"
at the macro scale through local interactions only, and without a clear notion of body/sensor/actuator.
In closing this blogpost, let us reiterate that what is interesting in such a system is that the computation of decision is done at the macro (group) level, showing how a group of simple identical entities can make "decision" and "sense" at the macro scale through local interactions only, and without a clear notion of body/sensor/actuator. Seeing the discovered creatures, it's even hard to believe that they are in fact made of tiny parts all behaving under the same rules. While some basic sensorimotor capabilities (spatially localized and moving entities) has already been found in Lenia with random search and basic evolutionary algorithms, this work makes a step forward showing how Lenia's low-level rules can self-organize robust sensorimotor agents with strong adaptivity and generalization to out-of-distribution perturbations.
Moreover, this work provides a more systematic method based on gradient descent, diversity search and curriculum-driven exploration to easily learn the update rule and initialization state, from scratch in high dimensional parameters space, leading to the emergence of different robust creatures with sensorimotor capabilities. We believe that the set of tools presented here can be useful in general to discover parameters that lead to complex self-organized behaviors.
Yet, most of the analyses we make in this work are subjective. Future work might want to have a better definition of agency and sensorimotor capabilities by defining a measure of such behavior.
Also, engineering subparts of the environmental dynamics with functional constraints (through predefined channels and kernels) has been crucial in this work to shape the search process towards the emergence of sensorimotor capabilities, as well as used as a tool to analyze more easily these emergent sensorimotor capabilities. An interesting direction for future work is to add even more constraints in the environment such as the need for food/energy to survive, the principle of mass conservation, or even the need to develop some kind of memory to anticipate future perturbations. We believe that richer environmental constraints and opportunities might be a great leap forward in the search for more advanced agent behaviors. For example, behaviors like competition between individuals/species for food, foraging or even basic forms of learning might emerge. From this competition and new constraints, interesting strategies could emerge as a form of autocurricula, as in .
In fact, beyond individual capabilities, we could even wonder under what conditions one could observe the emergence
of an open-ended evolutionary process directly in the environment, without any outer algorithm, resulting
in the emergence of agents with increasingly complex behaviors.
In fact, beyond individual capabilities, we could even wonder under what conditions one could observe the emergence of an open-ended evolutionary process directly in the environment, without any outer algorithm, resulting in the emergence of agents with increasingly complex behaviors. Like building the physical rules of an "Universe" and letting agency and evolution emerge from the interactions between parts. To achieve this, we might need to use an optimization process similar to the one presented in this blogpost to evolve all the environmental rules instead of pre-specifying some of them by hand. Indeed, while the engineering of specific environmental rules facilitates the understanding/studying of the results (e.g. talking of "creature" and "wall" channels), having more systematic ways to generate them could take us closer to the fundamental scientific quest of designing open-ended artificial systems with forms of functional life and agency "as it could be".
Despite those fundamental scientific questions, future work might also consider the biological implications and applications of this work. Inferring low-level rules to control complex system-level behaviors is a key problem in regenerative medicine and synthetic bioengineering . In this regard, cellular automata offer an interesting framework to model, understand and control the emergence of growth, form and function in self-organizing systems. However, they remain abstract toy models: entities in the CA exist on a predefined grid topology whereas physical entities have continuous position and speed ; states in the CA are well-defined whereas it is not clear where and how information is processed in living organisms; rules in the CA operate at a predetermined scale whereas real-world processes operate at nested and interconnected scales. Far from trivial, transferring insights from artificial systems to real physical and biological systems is an exciting area of research with a potential broad range of medical, environmental and societal applications .