Targeted audience: AI researchers, AI engineers
Expected reading time: ~10 minutes
Useful links:
1) What is a world model?
What if I told you that a car is speeding toward a cliff?
You probably didn’t just picture the scene—you also imagined what happens next: the car going over the edge and crashing below.
This automatic response relies on an internal simulation—an implicit model of how the world works. Humans continuously build and refine such internal world models [1,2]. These models are at play whenever we imagine, plan, reason, or react to situations.
In that sense, world models are fundamental to human intelligence.
But what about AI systems?
Recently, building world models has gained significant attention. Approaches such as JEPA and its associated architectures [3,4,5], or DINO-WM [6], aim to learn representations that can predict how observations evolve over time. Concretely, given a sensory input (e.g., a video frame), these models are trained to predict what comes next.
This trend is partly motivated by a perceived limitation of current AI systems. Large Language Models (LLMs), despite their impressive capabilities, are often argued to lack a true understanding of the physical world [7,8,9]. This is largely attributed to their training objectives: next-token prediction and human-feedback maximization incentivize fluent, plausible text generation, but do not inherently require—or reward—building an accurate model of how the world works.
However, the idea of world models is not new [10,11].
In the reinforcement learning literature, world models have long been studied under the umbrella of model-based reinforcement learning [10,11,12,13]. In this setting, an agent learns a model of its environment through interaction, and uses it to simulate future outcomes. This allows the agent to select actions by imagining their consequences before acting—or even to learn entirely from imagined experience.
What has changed, then, is not the idea itself but its renewed prominence—and with it, a deeper question: what kind of world model is needed?
2) Building world models
One increasingly popular answer is to learn world models directly from large-scale sensory data—the path advocated by researchers such as Yann LeCun and instantiated by the JEPA-style architectures and DINO-WM mentioned earlier [3,4,5,6]. These models are trained in a self-supervised fashion: given a stream of observations (e.g., consecutive video frames), part of the input is masked or withheld, and the model learns to predict the missing or upcoming content—typically in a learned representation space rather than at the level of raw pixels. Repeated over massive amounts of data, this yields representations that capture how observations tend to evolve over time.
But is this the only path forward?
To answer this, it is important to revisit what we mean by a world model. In much of the AI literature, the term is used in a relatively narrow sense: a system that predicts future observations.
In contrast, cognitive science adopts a broader perspective. Human mental models are not limited to prediction—they also support explanation, abstraction, and counterfactual reasoning. For example, the theory theory suggests that humans understand the world through intuitive theories. These range from simple rules (e.g., “gravity makes objects fall”) to more structured representations, such as mathematical models. More abstract forms of world models have also been explored in AI, including Bayesian networks and program-like representations [14,15].
Another important observation in humans is that mental models are not learned passively (which strongly contrasts from how most recent approaches train world models).
While children do learn from observation, a key component of acquiring a robust world model is interaction. Humans actively explore their environment: they experiment, observe outcomes, and refine their internal models accordingly.
This process is often described as curiosity-driven exploration—a form of behavior aimed at gathering informative experiences rather than maximizing immediate reward [16,17,18]. This loop of exploration and model refinement is not unique to artificial agents. It mirrors what developmental psychologists argue is a core driver of children’s cognitive growth [19]—and, at a higher level, it is precisely what scientists do: form hypotheses, design experiments to test them, and revise their understanding accordingly.
A similar insight has emerged in AI. In reinforcement learning, purely random exploration is often insufficient to learn accurate models of the environment. Instead, agents benefit from exploration strategies that prioritize informative or novel situations, enabling more efficient learning of world dynamics.
In that sense, building world models is not just a matter of prediction—it fundamentally relies on how data is collected. Effective world models emerge from meaningful, information-driven interaction with the environment.
3) WorldLLM: curious LLMs that explore and refine their world model
In our team, studying curiosity-driven exploration has been a central topic, from modelling curiosity in humans (and in particular children) to designing curious artificial agents. In recent years, we’ve proposed several approaches for augmenting LLMs with curiosity-based exploration [20,21], allowing them to set and learn their own goals (i.e., turning them into autotelic agents [21,22]). Building on this line of work, WorldLLM—led by Guillaume Levy and colleagues—asks whether an LLM can go a step further and actively build an abstract model of its environment through interaction, by combining curiosity-driven exploration with language-based reasoning.
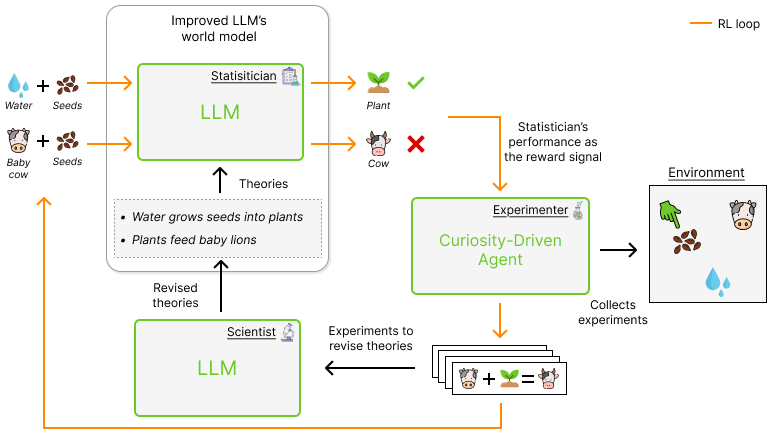
More specifically, WorldLLM embodies an LLM in an agent that acts in an environment, collects experiences it struggles to predict, and generates natural-language theories to explain—and ultimately better predict—what it observes. Crucially, the resulting world model is not a neural network fitted to data, but a set of abstract theories expressed in natural language: human-readable, interpretable, and stated explicitly rather than buried in a model’s weights.
In this respect, the agent behaves much like a scientist: it confronts the limits of its current understanding, formulates explanatory hypotheses, and tests them against reality. This framing connects to a recent wave of work on artificial automated scientists, where LLMs autonomously generate ideas, run experiments, and write up findings [23,24]. WorldLLM shares the same spirit, but targets a more fundamental ingredient: building and refining an abstract model of how the world works.
This makes it worth being explicit about what WorldLLM is and is not. It is not a new LLM, nor a new kind of LLM—it does not modify the architecture or training of the underlying language model. It is an agentic architecture wrapped around an existing LLM. And unlike most LLM agents today, which are built to write code or carry out user-defined tasks, WorldLLM’s agent has a different purpose entirely: to formulate hypotheses about its environment and put them to the test through active experimentation. Its capability lies not in any single model call, but in the loop of acting, observing, and revising.
To do this, WorldLLM frames the acquisition of a world model as a process of Bayesian inference over theories. Rather than learning a single predictive model, the system maintains a distribution over possible explanations of the environment, where each theory is a structured, language-based hypothesis about how the world behaves. The space of such theories is vast—and this is where the LLM becomes essential.
The LLM plays a dual role. On one hand, it predicts observations, conditioning on a candidate theory supplied in its prompt. On the other, it acts as a proposal mechanism, generating new theories meant to explain past observations—effectively serving as a learned prior over plausible, structured hypotheses.
These theories are not judged in the abstract: they are tested through interaction. The agent collects new observations, and the LLM assesses how well each theory accounts for them. Reinforcement learning drives this data collection, and—critically—the exploration is curiosity-driven. Rather than passively observing, the agent is rewarded for seeking out the most informative situations: those where competing theories disagree, or where the current model is most uncertain. This closes a learning loop that is, again, fundamentally agentic: propose theories → test them through interaction → observe outcomes → update beliefs
Over time, the agent sharpens its distribution over theories, favoring those that help the LLM better explain what it encounters. In doing so, WorldLLM ties language-based reasoning to environment interaction, grounding theories expressed in language by testing them through experience.
When evaluated in a textual environment where an agent must manipulate and combine objects, WorldLLM not only improves predictive accuracy but also yields human-interpretable theories of the environment’s dynamics, making explicit what the system has come to understand.
4) From prediction to understanding
World models have long been framed as predictive tools: systems that learn to anticipate what comes next. But as we have seen, prediction alone may not be enough.
Humans do not just passively model the world—we form hypotheses, test them through interaction, and refine them over time. Our understanding emerges not only from data, but from how we choose to collect it.
Rather than treating LLMs as static predictors, WorldLLM embeds them in a loop of hypothesis generation, experimentation, and belief updating. The LLM is no longer just a model of text—it becomes part of a system that actively seeks to understand the world. As mentioned at the beginning of Section 3, this is part of a broader line of work in our team on autotelic LLMs: studying how language models can explore, set their own goals, and learn to control their environment rather than merely describe it [7,20]. WorldLLM’s focus on building world models complements these earlier efforts to ground LLMs through interaction and to guide their exploration of large goal spaces—together sketching a view of LLMs as agents that learn from, and act upon, the world.
However, this perspective raises several open questions.
Can language-based theories capture the richness of physical and causal dynamics?
Should future AI systems rely more on interaction and exploration, rather than ever-larger static datasets?
Can current approaches used to build world models be used to capture models of others (i.e., Theory Of Mind)?
Acknowledgements
Thank you to Pierre-Yves Oudeyer for his thoughtful feedback and references.
References
[1] Craik, K. J. W. 1943. The Nature of Explanation. Cambridge University Press.
[2] Johnson-Laird, Philip Nicholas. 1983. Mental Models: Towards a Cognitive Science of Language, Inference, and Consciousness. Harvard University Press.
[3] Assran, Mido, Adrien Bardes, David Fan, et al. 2025. “V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning.”
[4] Bardes, Adrien, Jean Ponce, et Yann LeCun. 2023. “MC-JEPA: A Joint-Embedding Predictive Architecture for Self-Supervised Learning of Motion and Content Features.”
[5] Nam, Heejeong, Quentin Le Lidec, Lucas Maes, Yann LeCun, et Randall Balestriero. 2026. “Causal-JEPA: Learning World Models through Object-Level Latent Interventions”
[6] Zhou, Gaoyue, Hengkai Pan, Yann LeCun, et Lerrel Pinto. 2025. “DINO-WM: World Models on Pre-Trained Visual Features Enable Zero-Shot Planning.” Forty-second International Conference on Machine Learning.
[7] Romac, Clément, Thomas Carta, Pierre-Yves Oudeyer. “Can AIs understand our world? Functionally grounding LLMs in interactive environments.” https://developmentalsystems.org/glam.
[8] Zahavy, Tom. 2026. “LLMs can’t jump.”
[9] LeCun, Y. 2022. “A path towards autonomous machine intelligence version 0.9.2.” Open Review, 62(1), 1–62.
[10] Werbos, Paul J. 1987. “Learning How the World Works: Specifications for Predictive Networks in Robots and Brains.” Proceedings of the IEEE Conference on Systems, Man and Cybernetics.
[11] Sutton, Richard S. 1990. “Integrated Architectures for Learning, Planning, and Reacting Based on Approximating Dynamic Programming.” Proceedings of the Seventh International Conference on Machine Learning (ICML).
[12] Moore, Andrew W., et Christopher G. Atkeson. 1993. “Prioritized Sweeping: Reinforcement Learning with Less Data and Less Time.” Machine Learning 13(1): 103–130.
[13] Moerland, Thomas M., Joost Broekens, Aske Plaat, et Catholijn M. Jonker. 2023. “Model-Based Reinforcement Learning: A Survey.” Foundations and Trends in Machine Learning 16(1): 1–118.
[14] Piriyakulkij, Wasu T., Cassidy Langenfeld, Tuan A. Le, et Kevin Ellis. 2024. “Doing Experiments and Revising Rules with Natural Language and Probabilistic Reasoning.” Advances in Neural Information Processing Systems 37: 53102–37.
[15] Tsividis, Pedro A., Joao Loula, Jake Burga, et al. 2021. “Human-Level Reinforcement Learning through Theory-Based Modeling, Exploration, and Planning.”
[16] Baldassarre, Gianluca, et Marco Mirolli, éd. 2013. Intrinsically Motivated Learning in Natural and Artificial Systems. Springer.
[17] Oudeyer, Pierre-Yves, et Frederic Kaplan. 2007. “What Is Intrinsic Motivation? A Typology of Computational Approaches.” Frontiers in Neurorobotics 1.
[18] Schmidhuber, Jürgen. 1991. “A possibility for implementing curiosity and boredom in model-building neural controllers.” Proceedings of the first international conference on simulation of adaptive behavior on From animals to animats.
[19] Gopnik, Alison, Andrew N. Meltzoff, et Patricia K. Kuhl. 1999. The Scientist in the Crib: Minds, Brains, and How Children Learn. William Morrow & Company.
[20] Gaven, Loris, Thomas Carta, Clément Romac, Cédric Colas, Sylvain Lamprier, Olivier Sigaud, et Pierre-Yves Oudeyer. 2025. “MAGELLAN: Metacognitive Predictions of Learning Progress Guide Autotelic LLM Agents in Large Goal Spaces.” Proceedings of the 42nd International Conference on Machine Learning (ICML’25), Vol. 267.
[21] Colas, Cédric, Tristan Karch, Olivier Sigaud, et Pierre-Yves Oudeyer. 2022. “Autotelic Agents with Intrinsically Motivated Goal-Conditioned Reinforcement Learning: A Short Survey.” Journal of Artificial Intelligence Research 74.
[22] Steels, Luc. 2004. “The Autotelic Principle.” In Embodied Artificial Intelligence: International Seminar, Dagstuhl Castle, Germany, July 7-11, 2003. Revised Papers, edited by Fumiya Iida, Rolf Pfeifer, Luc Steels, and Yasuo Kuniyoshi. Springer.
[23] Lu, Chris, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, et David Ha. 2024. “The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery.”. arXiv:2408.06292
[24] Yamada, Yutaro, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, et David Ha. 2025. “The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search.”. arXiv:2504.08066